Abstract
Static application security testing lives with a tension between recall and precision. Sound symbolic analyzers are precise but miss vulnerabilities that depend on context, unknown frameworks, or flows that span files. Pattern scanners cast a wider net and pay for it in false positives. Pure-LLM scanners are broad but ungrounded and non-deterministic. Frame is a neuro-symbolic SAST built around one idea: keep a sound symbolic engine as the backbone, add an LLM for breadth, and have the symbolic engine ground and verify what the LLM proposes. The symbolic core does taint analysis and separation-logic verification with Z3. An optional LLM layer detects vulnerabilities the core misses, including cross-file flows, via an agentic loop that reads and greps the repository. It checks each proposal against the core’s own sink model and tiers findings so LLM output is never confused with proven results. A final pass triages away false positives. On the Endor Labs real-world corpus (five production applications, 193 model-judged pooled vulnerabilities) Frame’s full mode reaches 0.67 recall at 0.51 precision (F1 0.58) against Semgrep OSS’s 0.52 / 0.40 / 0.45. The LLM layer recovers about 65 confirmed vulnerabilities that both the symbolic engine and Semgrep miss, across Java, JavaScript/TypeScript, and C#, including a C# application where both traditional engines report nothing. The whole layer runs on a local model. We report the limitations of the evaluation candidly, including the fact that the pooled ground truth is enriched by Frame’s own LLM detection.
1. Introduction
A security scanner that a developer trusts has to be both precise and thorough. In practice tools sit at one end of that trade-off. Sound symbolic analysis proves properties and stays precise, but it only finds what its models can express: a taint spec it lacks, a framework it does not know, or a flow that crosses a file boundary the analysis did not follow. Pattern-based scanners match syntactic signatures across everything, so they surface more but bury the real findings in noise. A third option, prompting a large language model to find bugs, is broad and context-aware but ungrounded: it hallucinates flows, it is non-deterministic, and it offers no proof.
Frame takes a neuro-symbolic position. The symbolic engine is the sound backbone and stays the default. An LLM is added for what it is good at, breadth and context, and the symbolic engine is used to ground it. Concretely:
- The LLM detects vulnerabilities the symbolic core misses. For flows that span files it runs as an agent with
read_fileandgreptools over the repository. - Every LLM finding is checked against Frame’s own sink model. A finding whose claimed sink is one the symbolic engine recognizes is promoted to a higher-confidence tier. LLM output and proven symbolic output are never merged into one undifferentiated list.
- A triage pass drops confident false positives, recovering precision.
This report describes the architecture, the local-LLM implementation, and an evaluation on real-world code. Contributions:
- A neuro-symbolic SAST design where the symbolic engine grounds and tiers LLM findings rather than the LLM overriding the symbolic result.
- An agentic, cross-file detection loop driven by a local, OpenAI-compatible model.
- Symbolic sink-verification of LLM claims, including the cross-file case, which yields a high-precision subset.
- A real-world evaluation with an explicit, honest account of its limitations.
The headline is one table. Everything after it is how we got there and why the numbers should be read with care.
| Scanner | Recall | Precision | F1 |
|---|---|---|---|
| Frame, symbolic core only | 0.37 | 0.45 | 0.41 |
| Frame, + LLM detection | 0.71 | 0.46 | 0.56 |
| Frame, + LLM detection + triage | 0.67 | 0.51 | 0.58 |
Semgrep OSS (p/default) | 0.52 | 0.40 | 0.45 |
| Endor AI SAST (published, different ground truth) | 0.44 | 0.50 | 0.47 |
2. Motivating examples
Precision: a finding that is real-looking but not real. Frame’s symbolic layer, run over a real application, flags a regular-expression denial-of-service pattern inside a bundled, minified JavaScript library it ships. The pattern is there, but the library code is not reachable from any request the application serves. Across the corpus, 264 of Frame’s 371 symbolic false positives are exactly this class: CWE-1333 (ReDoS) and CWE-1321 (prototype pollution) matched inside vendored libraries. A tool that reports them is not wrong about the syntax; it is wrong about the context. Triage exists to remove them.
Recall: a vulnerability the symbolic engine cannot express. Consider this handler from the C# application in the corpus (DotNetFlicks.Web/Controllers/MovieController.cs):
/*Sprinkle on some CSRF
*[ValidateAntiForgeryToken]
*/
[HttpPost]
public ActionResult Edit(EditMovieViewModel vm)
{
...
}This is a state-changing POST action whose anti-forgery-token attribute has been commented out. It is a cross-site request forgery vulnerability (CWE-352). No taint reaches a sink here; the bug is the absence of a control, expressed as a comment. A symbolic engine has nothing to prove. A reader who understands ASP.NET sees it at once. This is the kind of finding the LLM layer is meant to add.
Why not just prompt an LLM. Endor Labs’ own published comparison puts a strong general model (Claude Opus 4.7) at 0.718 precision with near-bottom recall on this corpus. Broad prompting alone is neither complete nor grounded. The design question is not “LLM or symbolic” but “how does the symbolic engine keep the LLM honest.”
3. Architecture

Source code is parsed by a per-language frontend into SIL, Frame’s intermediate representation. From SIL the two layers proceed.
Symbolic core (always on). Taint analysis tracks untrusted data from sources to sinks; separation logic reasons about the heap; Z3 discharges the resulting queries. What survives is a set of proven findings. This layer is sound in the sense that it reports a taint-to-sink vulnerability only when it can construct the flow. It is the default, and it is unchanged by anything the LLM layer does.
LLM detection (optional). On security-relevant files the model is asked, with the file in context, to report genuine vulnerabilities as structured JSON. When a repository root is configured the model runs as an agent: it may call read_file and grep to inspect other files (helpers, callers, configuration, sinks defined elsewhere) before deciding. This is how cross-file flows are found.
Symbolic verification and tiering. Each LLM finding is checked against Frame’s own sink model. Frame collects the sinks its symbolic layer recognizes, in the reported file and in every file the agent read, and asks whether a sink of the finding’s vulnerability class sits at the claimed location. If so, the finding is promoted to the llm_verified tier: the LLM supplied a flow the symbolic engine could not complete, but the dangerous operation at the end of that flow is one Frame independently recognizes. Findings that do not ground stay in the lower llm_detect tier. Proven symbolic findings are never relabeled.
Triage (optional). A final pass asks the model whether each finding is a true positive and drops the ones it rejects with high confidence. When detection and triage are both enabled, detection runs first so that triage also filters the noisier detection output.
The invariant across the layers: the LLM proposes, the symbolic engine verifies, and no LLM output is presented as proven. A user can act on the symbolic findings with the same confidence as before and treat the LLM tiers as leads of graded strength.
4. Implementation
The LLM layers speak to any OpenAI-compatible /v1/chat/completions endpoint, so the model can be a hosted frontier model or a local one. The results in this report use a local model, for privacy and cost: mlx-community/Qwen3.6-35B-A3B-OptiQ-4bit, served on Apple Silicon with mlx-optiq:
pip install mlx-optiq
optiq kv-cache mlx-community/Qwen3.6-35B-A3B-OptiQ-4bit --target-bits 5.0 -o ./kv
optiq serve --model mlx-community/Qwen3.6-35B-A3B-OptiQ-4bit \
--kv-config ./kv/kv_config.json --port 47317 --mtpWe validated two capabilities the agentic loop needs. Tool calling works: given a tool schema, the server returns well-formed tool_calls. Long context works: a 13.5k-token request that buries one vulnerable line in filler is answered correctly. Latency on this setup is about 5 seconds per tool-calling round and about 24 seconds for a 13.5k-token read. That is slow next to a symbolic scan, which is why the layer is opt-in, but a local model makes deep, iterative exploration free to run.
Detection uses structured JSON output and fails safe: any transport or parse error yields no findings rather than a guess. A candidate heuristic keeps a scan tractable by sending only security-relevant files to the model (request handlers, database and process calls, file and template operations, deserialization, and the ASP.NET equivalents). The layers are off by default and are enabled with frame scan --ai or FrameScanner(llm_detect=True, llm_triage=True).
5. Evaluation methodology
Corpus. We use the five real-world applications Endor Labs named in their public AI-SAST benchmark: anonymous-github, demo-netflicks, juice-shop, webgoat, and shopizer. We exclude the three non-application entries in their list: OWASP BenchmarkJava (synthetic, and already covered by Frame’s main benchmarks), doublestar (Go, unsupported), and the XBOW set (mostly PHP, unsupported).
Pooled ground truth. Real applications ship no labels. We build a pooled ground truth: run Frame (symbolic and its LLM detection layer) and Semgrep OSS, adjudicate every finding with an LLM judge (Claude Sonnet 5, one finding at a time, reading a window around each), and keep the union of confirmed true positives. The result is 193 vulnerabilities. This is a lower bound. It contains only vulnerabilities some engine found and the judge confirmed; anything all engines missed is absent, so a finding outside the set is not necessarily a false positive.
| Repository | Language(s) | Pooled vulns |
|---|---|---|
| webgoat | Java, JS/TS | 73 |
| juice-shop | JS/TS | 72 |
| shopizer | Java, JS/TS | 29 |
| anonymous-github | JS/TS | 12 |
| demo-netflicks | C#, JS | 7 |
| Total | 193 |
Judge validation. The judge is a stand-in for manual review, so we checked it against real labels. On a BenchmarkJava sample, where ground truth is known, the Sonnet 5 judge agreed with the official labels about 89% of the time. Labels carry a claude_code:* source so they stay distinct from any hand-validated set.
Matching. A finding matches a ground-truth entry on the same file and the same CWE. We match on file and CWE rather than exact line because two tools routinely report the same vulnerability at different lines (the query is built on one line and executed several lines later). Closely equivalent CWE families are normalized (for example CWE-73 and CWE-22, CWE-89 sibling classes) so no tool is penalized for a labeling choice. Recall is matched entries over 193; precision is true positives over judged findings.
6. Results
Main comparison. Figure 2 shows recall, precision, and F1 for each configuration.
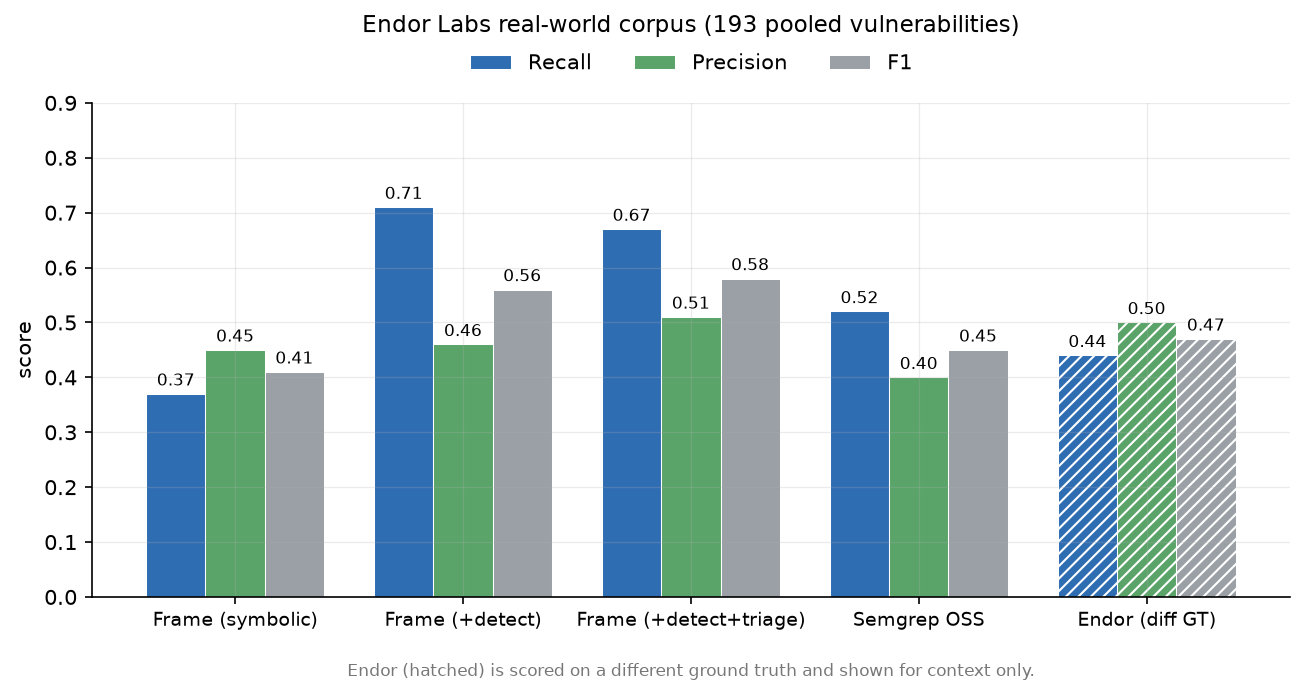
Frame’s full mode beats Semgrep OSS on all three axes. Endor’s published numbers are shown for context only and are hatched, because they are computed on Endor’s own larger, many-tool, manually-reviewed ground truth, a different denominator that is not comparable to this harness.
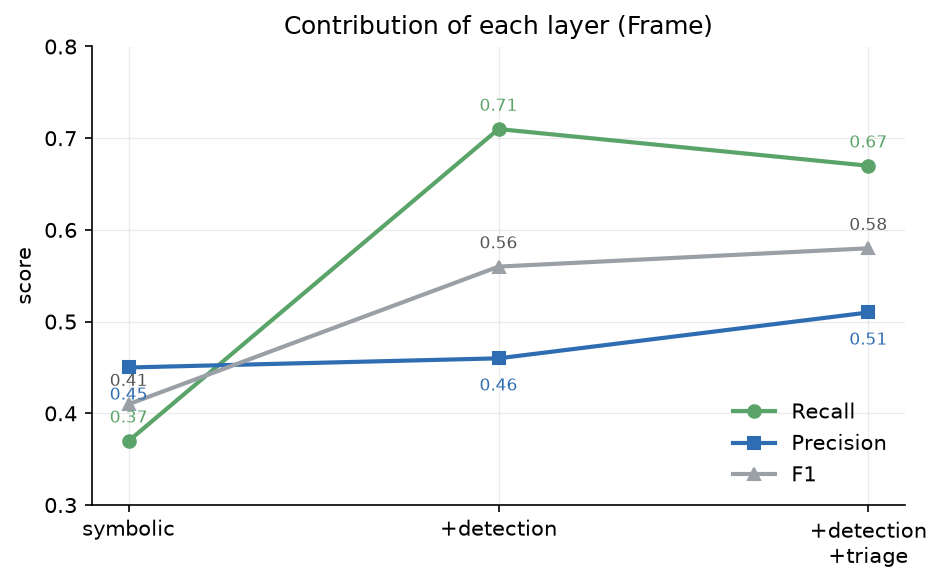
What each layer contributes. Figure 3 traces the layers. The symbolic core alone reaches 0.37 recall at 0.45 precision. Adding LLM detection lifts recall to 0.71, at a small precision cost. Adding triage trades a little of that recall back for precision, landing at 0.67 recall and 0.51 precision, the best F1 of the three.
Where the LLM layer helps. Figure 5 breaks coverage down by repository. The pattern is not uniform. On webgoat and juice-shop the symbolic core already finds a large share and the LLM adds a substantial tail. On shopizer the symbolic core finds 1 of 29 and the LLM adds 16. On demo-netflicks the symbolic core finds 0 and the LLM adds 5, all in C#. The gap between each bar and the ground-truth marker is what neither Frame nor Semgrep found.
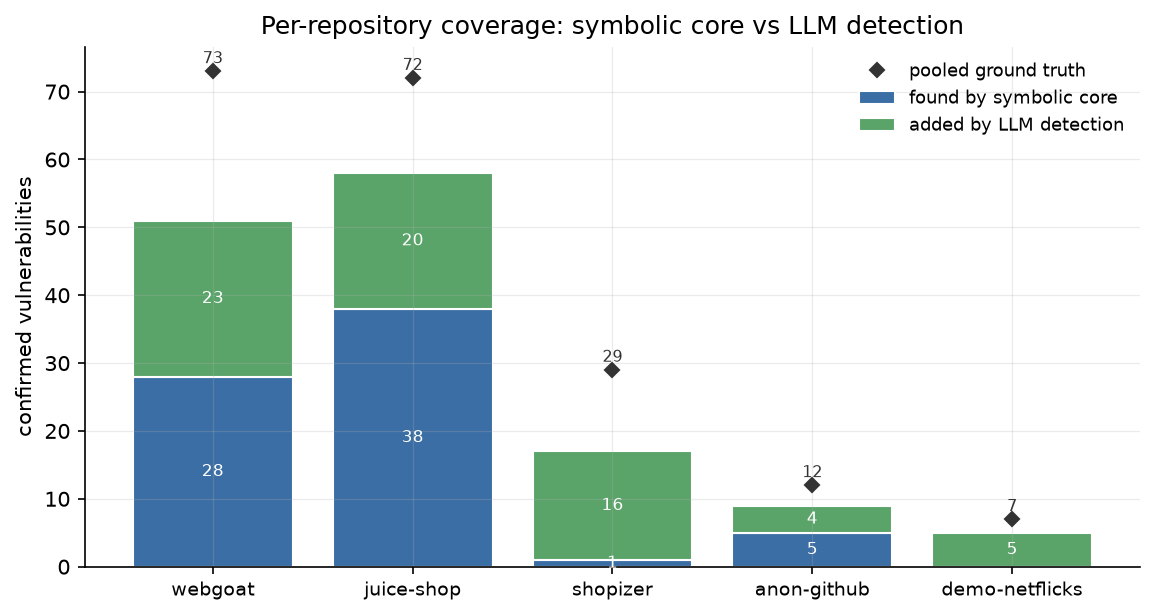
In total the LLM layer contributes 68 confirmed detections (about 65 net after de-duplication against existing entries), spanning Java, JavaScript/TypeScript, and C#. Every one is a vulnerability that both Frame’s symbolic engine and Semgrep miss.
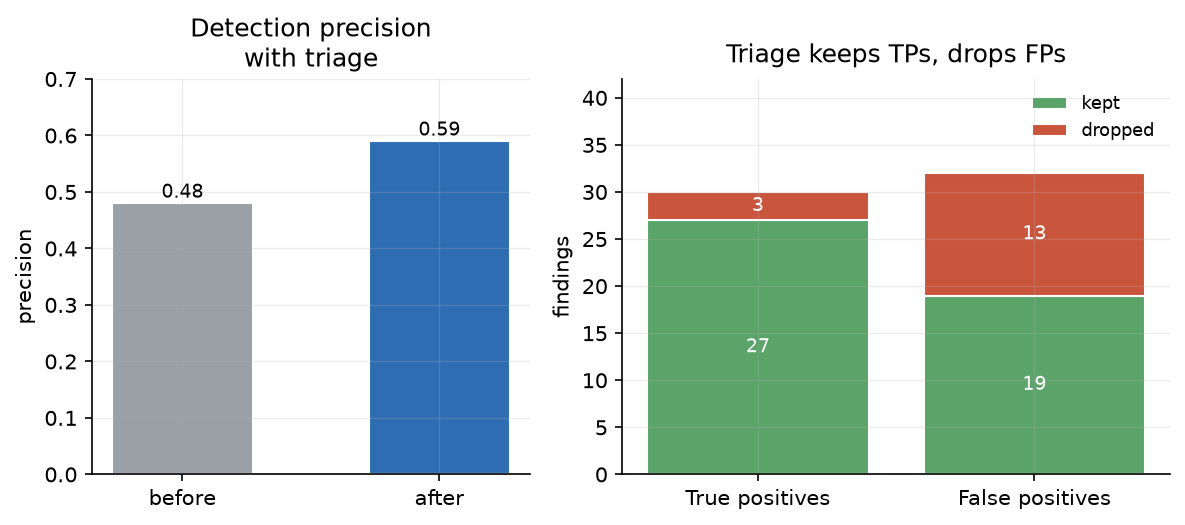
Triage. Figure 4 shows the triage pass measured on the detection output. It keeps 27 of 30 true positives (90%) and drops 13 of 32 false positives (41%), moving detection precision from 0.48 to 0.59. Triage is the same local model taking a second, skeptical look at its own detections.
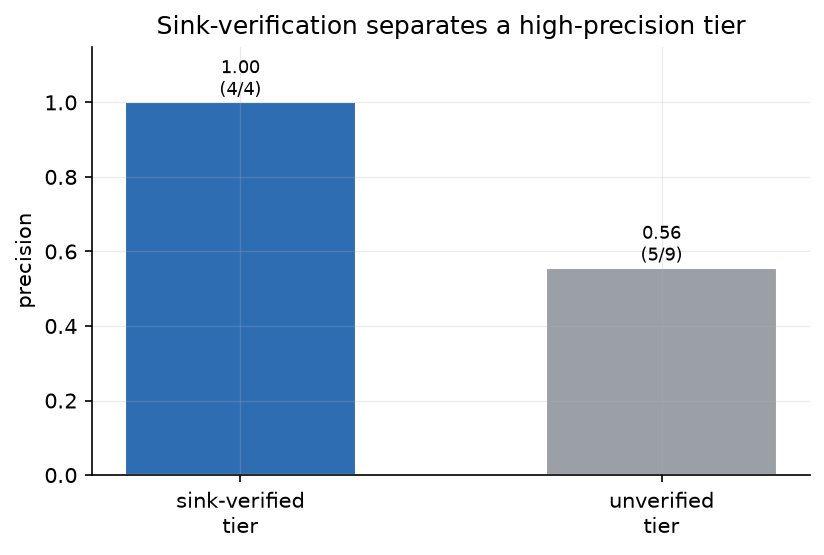
Verification. Figure 6 shows the effect of sink-verification on a judged sample. The sink-verified tier is 4 for 4 true positives; the unverified tier is 5 true positives against 4 false positives. Grounding a finding in a sink the symbolic engine recognizes is a strong precision signal. It does not catch everything, because some real vulnerabilities are in classes Frame has no sink model for (verbose-error information exposure, for instance), which is why the unverified tier is kept rather than discarded.
7. Case studies
7.1 Triage removes a context false positive. The 264 vendored-library matches from Section 2 are the bulk of the symbolic layer’s false positives. They are syntactically real regex or object-merge patterns sitting in code the application never reaches from a request. Triage, reading the surrounding context, rejects them. This is the mechanism behind the precision recovery in Figure 4.
7.2 Single-file detection recovers an interprocedural SQL injection. From webgoat (SqlInjectionLesson5.java):
public AttackResult completed(String query) { // request-derived parameter
createUser();
return injectableQuery(query);
}
protected AttackResult injectableQuery(String query) {
try (Connection connection = dataSource.getConnection()) {
try (Statement statement = connection.createStatement(...)) {
statement.executeQuery(query); // sink
...The request parameter flows through completed into injectableQuery and reaches executeQuery. The symbolic engine did not connect this particular chain. The LLM reported it as CWE-89, and because executeQuery is a sink Frame recognizes, verification promoted it to the llm_verified tier. The judge confirmed it.
7.3 Agentic detection follows a flow across files. Detection was run on a handler that delegates to a helper in another file:
// route.js
const helper = require('./dbHelper');
app.get('/products', (req, res) => {
const term = req.query.q; // attacker-controlled
helper.searchProducts(term, res); // delegated to another file
});// dbHelper.js
exports.searchProducts = (term, res) => {
const sql = "SELECT * FROM products WHERE name LIKE '%" + term + "%'"; // sink
db.query(sql, (e, rows) => res.json(rows));
};The recorded tool-call trace, verbatim:
read_file { "path": "dbHelper.js" }
-> const db = require('./db');
exports.searchProducts = (term, res) => {
const sql = "SELECT * FROM products WHERE name LIKE '%" + term + "%'";
db.query(sql, ...);
grep { "pattern": "db\\.query" }
-> dbHelper.js:4: db.query(sql, (e, rows) => res.json(rows));
finding: CWE-89 at route.js:4 (tier: llm_detect)
"User-controlled input req.query.q is directly concatenated into a SQL
string without parameterization, enabling SQL injection via the
searchProducts function in dbHelper.js."The source and the sink are in different files. The agent read the helper, confirmed the sink with a grep, and reported the flow, three model calls end to end. Neither single-file analysis nor a taint engine that does not cross this boundary would connect it.
7.4 C# coverage where both traditional engines report nothing. demo-netflicks is an ASP.NET application whose logic is in C#. Frame’s symbolic C# analysis parses all 115 files and reports zero vulnerabilities; Semgrep reports zero true positives (its only output on this repo is 32 false positives in vendored JavaScript). The LLM layer found five real vulnerabilities. One (DotNetFlicks.Accessors/Accessors/MovieAccessor.cs):
_db.Database.ExecuteSqlRaw(
"INSERT INTO UserSearches ([UserId],[SearchTerm]) Values ('"
+ request.UserId + "','" + request.Search + "')");Request fields are concatenated straight into ExecuteSqlRaw: SQL injection, CWE-89. The others include the commented-out anti-forgery token from Section 2 (CWE-352), a command injection and a path traversal in the sign-in manager, and an XXE. On this application the LLM layer is the only source of coverage either tool provides.
8. Threats to validity
Asymmetric ground truth. This is the most important caveat. The pooled ground truth is enriched by Frame’s own LLM detection: about 65 of the 193 vulnerabilities were surfaced by Frame’s LLM layer, which Semgrep, as shipped, has no mechanism to find. A fair AI-SAST-versus-AI-SAST comparison would give Semgrep an LLM layer too. The vulnerabilities are real and Semgrep genuinely misses them, but the magnitude of Frame’s recall lead reflects one-sided tooling. Semgrep’s recall is measured against a denominator Frame helped grow. We report the number and the reason together.
Model-adjudicated labels. Ground truth is judged by an LLM, not by hand. Agreement with real labels was about 89% on a synthetic sample. This is a fast, imperfect stand-in for human review. Treat every number as resting on that 89%.
Agentic noise. Agentic detection is noisier than single-file detection, with raw precision between 0.43 and 0.56. Verification and triage recover it, but the raw layer is not something to ship unfiltered.
Non-determinism. The LLM layers are non-deterministic. Runs vary. The symbolic core is deterministic; the LLM tiers are not, which is one reason they are opt-in and clearly separated.
Generalization. Five applications in three languages are a start, not a population. The C# result in particular rests on one application.
9. Related work
SMT-based separation logic reduces heap reasoning to first-order queries (the heap-as-array encoding), which is the basis of Frame’s symbolic core. Symbolic and abstract-interpretation analyzers such as Infer and Grasshopper prove memory and shape properties. Pattern-based scanners such as Semgrep and CodeQL match syntactic and dataflow signatures at scale. A growing line of work prompts LLMs to find vulnerabilities directly; Endor Labs’ AI-SAST benchmark reports both an LLM-driven detector and traditional baselines on real-world code. Frame differs from the pure-LLM line by keeping a sound symbolic engine as the backbone and using it to verify and tier LLM output. It differs from the symbolic line by using an LLM to reach findings the symbolic models cannot express.
10. Conclusion
Sound symbolic analysis and LLMs are complementary. Kept apart, each has a known failure mode: the symbolic engine misses what its models cannot express, and the LLM invents what it cannot prove. Frame puts them together with the symbolic engine in charge of the truth: it detects with the LLM, verifies with the symbolic sink model, tiers so nothing is confused with a proof, and triages away the noise. On real-world code the result is higher recall and higher precision than a mature pattern scanner, on a local model, with every finding either proven or clearly labeled. The honest asterisk is the asymmetric ground truth, and we would rather state it than hide it.
Artifacts, the pooled ground truth, and the harness are in the Frame repository.